Shared database antipattern. A three-legged race

In software development, we often make decisions that look like an excellent idea in the short run but result in the horror of maintenance down the road.
Letting two independent services use a shared database is one of those ideas.
More often, I’ve seen a less obvious variant. There’s a legacy system that’s hard to maintain. When the business needs new functionality quickly, they recruit new developers to create a better service from scratch. To use the legacy system data, the development team explores existing data structures and connects their new code to the old database.
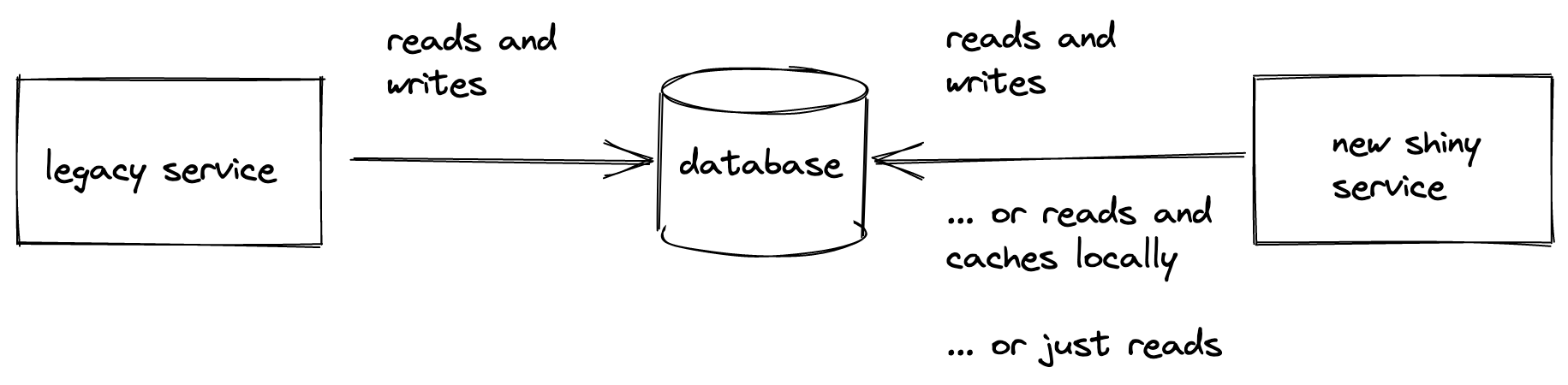
Two services sharing the database
It looks like an elegant win-win solution: stakeholders get their functionality, and developers build the solution quickly on a new, tech-debt-free codebase. In reality, though, it’s an increase in tech debt.
The solution reminds me of a three-legged race, a running event where pairs of athletes are tied to each other with a rope by their legs. The teams rush forward for the prize but continuously fall down for the amusement of the audience.
When tied by a rope of a shared database, both systems become more rigid and brittle.
- Database schema evolution becomes more complex – developers prefer not to touch tables if they know their changes can affect something they don’t control.
- Caching and cache invalidation become a can of worms – you never know if you need to wait a few hours until your peer system invalidates their cache.
- Events notifying third parties of changes become impossible if both systems use the shared database to write.
Communicating through a non-documented implicit interface is what prevents a seemingly harmless idea from working in practice. Like athletes in the race coordinating each movement with their peers, the developers of two systems have to coordinate their efforts with each other.