Time Series Caching with Python and Redis
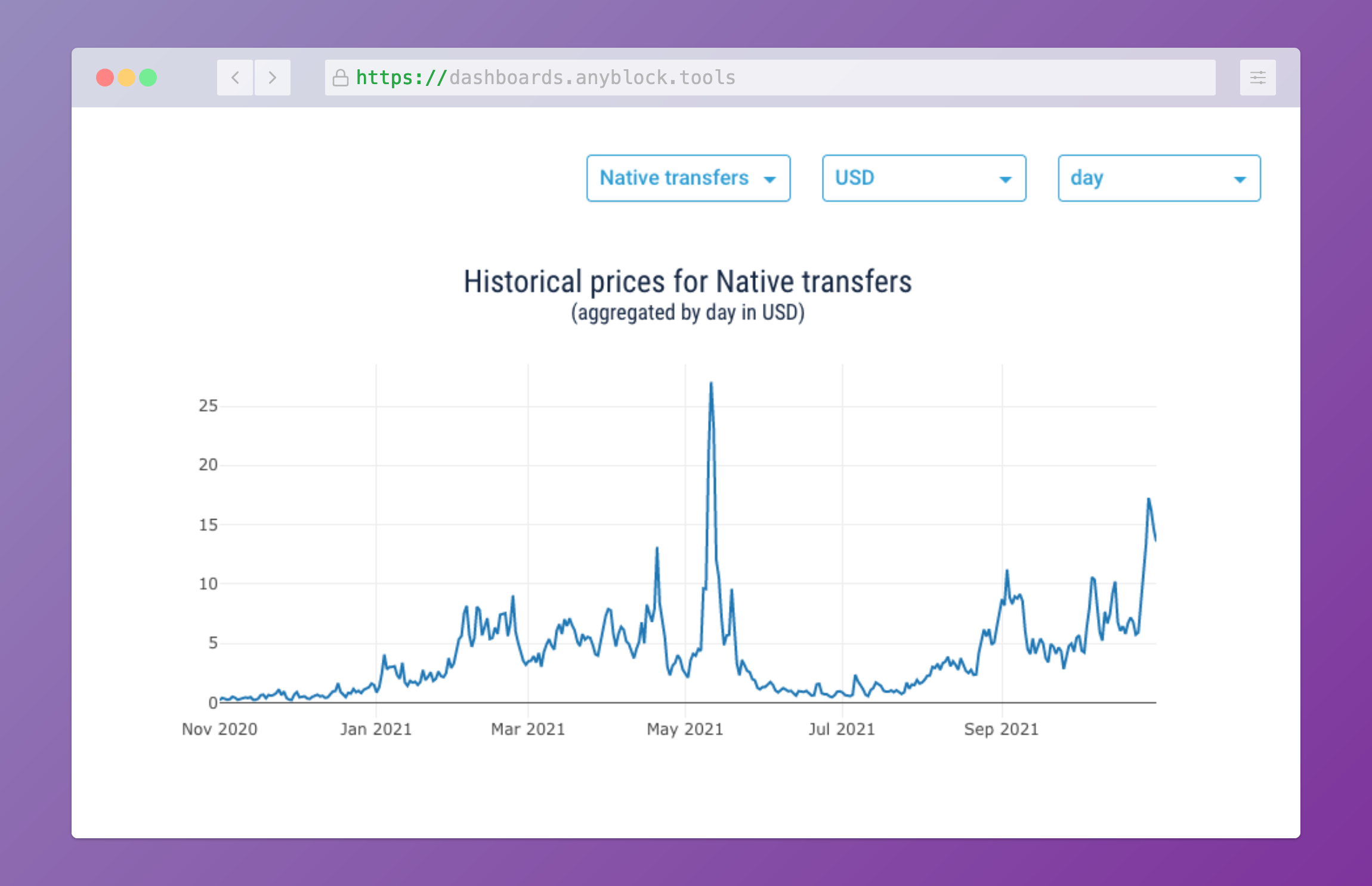
Time series plot for historical pricing of Ethereum transfers
Some takeaways on practical time series caching with Python and Redis from the Dashboards project that I implemented with Anyblock Analytics in 2021. The full code of the sample project is available at github.com/imankulov/time-series-caching.
TLDR. We replaced a generic Flask-caching solution with caching by date buckets, and I liked it.
I like it so much that I decided to write a blog post, sharing how we came to the solution. More specifically:
- How we took advantage of pydantic models in serializing cached data and why we should stay away from pickles.
- How we decoupled querying from caching and implemented a common date bucket caching solution with Python generic classes.
- How we populated the cache in the background with APScheduler.
The solution is accompanied by the sample Plotly Dash project. If you want to see the bigger picture, go ahead to github.com/imankulov/time-series-caching. Whenever possible, I provide direct links to the app.py file from the repository.
Problem introduction
Imagine you want to show a plot of a series of events. The task is trivial if you have your data at hand, but if you need to pull data from a slow upstream, you cache the data locally. You also pre-populate the cache for hot spots, e.g., the last few minutes or hours.
In our case, our upstreams were our own ElasticSearch cluster, the Web3 RPC proxies, and some third-party API endpoints.
To picture a more concrete example, imagine that you want to show a plot of all BTC transactions for a specific Bitcoin wallet and let the user choose the date range.
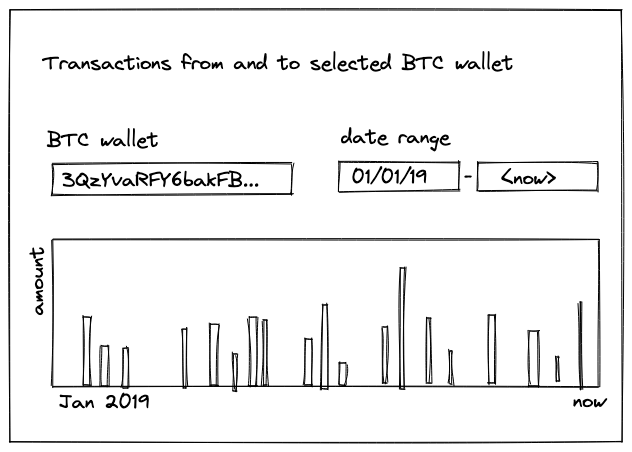
Sample BTC dashboard
Where to find the data
For the context of this post, the actual implementation of the query is not that important. In this example, as well as in the original dashboard, we’ll use the ElasticSearch interface provided by Anyblock Analytics.
The query function can look like this:
import datetime
import pydantic
from elasticsearch_dsl import Search
class Transaction(pydantic.BaseModel):
timestamp: datetime.datetime
amount: int
address: str
class Config:
frozen = True
def fetch_transactions(
wallet_address: str, start_date: datetime, end_date: datetime
) -> list[Transaction]:
...
Some notes about this code.
- This code will work with Python 3.9 or newer.
- The code depends on two external dependencies: elasticsearch-dsl and pydantic. Elasticsearch DSL is a convenience wrapper around the standard Python ElasticSearch client, and we use pydantic to describe the shape of the returned data.
This code reflects a convention we used throughout the project: query functions always require start and end dates and always return the ordered list of pydantic models. Each of the returned objects in the list represents a single element of time series.
We prefer explicit typing. When working with complex data structures, we define them explicitly with pydantic models, strongly preferring them over dicts or Pandas data frames. I shared more thoughts on this in a post Don’t let dicts spoil your code.
Also, we prefer pydantic over built-in Python dataclasses for their serializing, deserializing, and validation superpower, which comes in handy in caching as we’ll see later.
Out-of-the-box approach to caching
The Python ecosystem provides multiple out-of-the-box caching solutions. The previous version of the dashboard used Flask-caching. Adding caching to the project used to look like this.
from datetime import timedelta, datetime
cache_ttl = int(timedelta(hours=3).total_seconds())
@cache.memoize(timeout=cache_ttl)
def fetch_transactions(
wallet_address: str, start_date: datetime, end_date: datetime
) -> list[Transaction]:
...
As simple as it is, this approach is a bit rigid. For example, you can’t control the serialization and cache invalidation strategies. If you want to replace pickle, you need to create your own serializer, which is not that hard, but the solution stops being “out of the box.” By the way, if you wonder why you should avoid using pickle as a data format, you can refer to Pickle’s nine flaws by Ned Batchelder, the author of Python coverage, or Don’t Pickle Your Data by Ben Frederickson.
Caching to JSON with pydantic
When replacing a generic solution with our own, we need to take care of cache keys and the serialization procedure. Here’s the pydantic-based manual solution.
import json
import redis
import pydantic
from datetime import timedelta, datetime
from pydantic import BaseModel
from pydantic.json import pydantic_encoder
client = redis.Redis()
cache_ttl = int(timedelta(hours=3).total_seconds())
class Transaction(BaseModel):
...
def fetch_transactions(
wallet_address: str, start_date: datetime, end_date: datetime
) -> list[Transaction]:
...
def fetch_transactions_with_cache(
wallet_address: str, start_date: datetime, end_date: datetime
) -> list[Transaction]:
cache_key = f"{wallet_address}:{start_date.timestamp()}:{end_date.timestamp()}"
cached_raw_value = client.get(cache_key)
if cached_raw_value is not None:
return pydantic.parse_raw_as(list[Transaction], cached_raw_value)
value = fetch_transactions(wallet_address, start_date, end_date)
raw_value = json.dumps(value, separators=(",", ":"), default=pydantic_encoder)
client.set(cache_key, raw_value, ex=cache_ttl)
return value
It’s not generic yet; you must wrap each function with its own “_with_cache()” wrapper, but we’ll address generalization down the road. We use pydantic magic to serialize and deserialize pydantic models transparently.
- It uses
json.dumps(..., default=pydantic_encoder)for serializing. The encoder is lightly documented in the JSON Dumping section of the documentation. - It uses
pydantic.parse_raw_as(...), a pydantic deserializer that accepts the expected data type and the serialized string. The “magical part” of that serializer is that it accepts not only pydantic models but pretty much any valid Python type, e.g.,list[Transaction]as in our case.
One immediate benefit of replacing pickle with pydantic is our ability to evolve the model. We can extend our Transaction object in a backward-compatible way. For example, we can add new records with default values without invalidating the cache, and pydantic takes care of constructing the new version of the object and filling all the gaps from the model definition.
One thing that we can explore (but we never did in our implementation) is to take advantage of the RedisJSON module for speed, safety, and rich manual cache operations.
Caching in buckets
Finally, it’s time to address the elephant in the room: the ineffectiveness of our caching strategy for random start and end dates.
Imagine a client fetches data for the current month. Then, in a subsequent request, the client changes the start date to pull the statistics for the two latest months. With the first request, we already cached the data for this month. Somehow it would be nice to reuse it, but our naive caching approach doesn’t let us do so. The only approach is to pull the entire new dataset and save it to the cache, wasting time and upstream resources.
In general, our caching strategy doesn’t take advantage of sharing cached data for overlapping range intervals.
Inspired by page caching
Fortunately, the problem is not new. The closest analog that came to my mind was the so-called page cache, an in-memory cache that operating systems keep for data read from disk.
The analogy between disk reads and our system:
| What is it? | File system page cache | Our Dashboards |
|---|---|---|
| Slow upstream | Disk | ElasticSearch, third-party APIs, etc. |
| Fast cache medium | Memory | Redis |
| Selection filter | byte range | date range |
The page cache approach is to never read individual bytes. Instead, they read and keep in cache pages, entire blocks of data.
If you want to dive a bit deeper into the page cache thing, you can check out, for example, an article Page Cache, the Affair Between Memory and Files. Here’s how it outlines the page cache in a nutshell.
All regular file I/O happens through the page cache. In x86 Linux, the kernel thinks of a file as a sequence of 4KB chunks. If you read a single byte from a file, the whole 4KB chunk containing the byte you asked for is read from disk and placed into the page cache.
These chunks are aligned, meaning that they can be stacked together if you read large portions of data, and the reader will only ask for missing chunks.
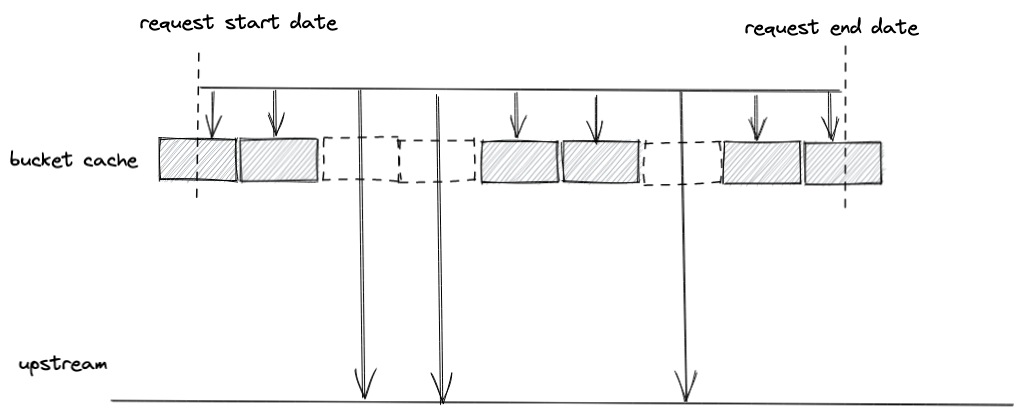
Caching in buckets
Weekly buckets
Replacing byte ranges with date ranges, we can build a bucket caching mechanism. Keeping our fetch_transactions intact, we only update the wrapper: fetch_transactions_with_cache.
First, introduce the model for date bucket. For the sake of simplicity, in the following example, we implement only weekly buckets. In the real project, we created buckets of different sizes.
week = timedelta(days=7)
class WeeklyBucket(BaseModel):
start: datetime
@property
def end(self) -> datetime:
return self.start + week
@validator("start")
def align_start(cls, v: datetime) -> datetime:
"""Align weekly bucket start date."""
seconds_in_week = week.total_seconds()
return datetime.fromtimestamp(
(v.timestamp() // seconds_in_week * seconds_in_week), timezone.utc
)
def next(self) -> "WeeklyBucket":
"""Return the next bucket."""
return WeeklyBucket(start=self.end)
We take advantage of pydantic validators. The function align_start() ensures that buckets can be stacked together. It converts the date to the closest past Thursday midnight UTC, no matter what time we pass. It’s Thursday because the Epoch Start, 1 Jan 1970 was a Thursday.
A few more things.
- Method
next()returns the next adjacent bucket. We’ll use it to create a series of buckets. - A calculated property
endreturns the bucket end date.
>>> WeeklyBucket(start=datetime.now(tz=timezone.utc))
WeeklyBucket(start=datetime.datetime(2021, 10, 21, 0, 0, tzinfo=datetime.timezone.utc))
Then we need a function that converts a date range into a list of weekly buckets.
def get_buckets(start_date: datetime, end_date: datetime) -> list[WeeklyBucket]:
...
Sample output:
In []: get_buckets(datetime(2020, 1, 1), datetime(2020, 2, 1))
Out[]:
[WeeklyBucket(start=datetime.datetime(2019, 12, 26, 0, 0)),
WeeklyBucket(start=datetime.datetime(2020, 1, 2, 0, 0)),
WeeklyBucket(start=datetime.datetime(2020, 1, 9, 0, 0)),
WeeklyBucket(start=datetime.datetime(2020, 1, 16, 0, 0)),
WeeklyBucket(start=datetime.datetime(2020, 1, 23, 0, 0))]
Now we can update our caching function.
import redis
import pydantic
import json
from datetime import timedelta, timezone, datetime
from pydantic import BaseModel
from pydantic.json import pydantic_encoder
client = redis.Redis()
class Transaction(BaseModel):
...
class WeeklyBucket(BaseModel):
...
def get_buckets(start_date: datetime, end_date: datetime) -> list[WeeklyBucket]:
...
def fetch_transactions(
wallet_address: str, start_date: datetime, end_date: datetime
) -> list[Transaction]:
...
def fetch_transactions_with_cache(
wallet_address: str, start_date: datetime, end_date: datetime
) -> list[Transaction]:
buckets = get_buckets(start_date, end_date)
transactions = []
for bucket in buckets:
cache_key = f"{wallet_address}:{bucket.cache_key()}"
cached_raw_value = client.get(cache_key)
if cached_raw_value is not None:
transactions += pydantic.parse_raw_as(list[Transaction], cached_raw_value)
continue
value = fetch_transactions(wallet_address, bucket.start, bucket.end)
raw_value = json.dumps(value, separators=(",", ":"), default=pydantic_encoder)
client.set(cache_key, raw_value, ex=get_cache_ttl(bucket))
transactions += value
return [tx for tx in transactions if start_date <= tx.timestamp < end_date]
def get_cache_ttl(bucket: WeeklyBucket):
if bucket.end >= datetime.now(tz=timezone.utc):
return int(timedelta(minutes=10).total_seconds())
return int(timedelta(days=30).total_seconds())
Some notes about the code beyond the “split and cache chunks” approach.
- We have a bonus point of choosing different caching strategies for different buckets. More specifically, we differentiate “open buckets” (buckets with the end date in the future) and “closed buckets” (buckets with the end date in the past) and choose a much shorter caching interval for open buckets than for closed ones.
- Because of a more efficient caching strategy, we can cache the tail for a much shorter interval (or even not cache it at all) without penalty. As for closed buckets, we can even cache them forever.
- Notice how we do extra filtering in the final return clause. We need it because of how fetching in buckets works—we may pull more data than we need, and we filter out records that fall outside the range.
Further optimizations
We can optimize the code above further. Below, I only outline the further optimization steps without going deeper into implementation details.
- Instead of fetching records from cache one by one with
client.get(), we can fetch them all at once with MGET. Redis returns None for missing keys, and these gaps should be processed withfetch_transactions. - The same goes for writing data back to the cache. There, we can resort to Redis Pipelines to speed up populating the cache.
- Finally, we notice that fetching data for different ranges is independent and can run in parallel. Instead of pulling missing data one by one in a cycle, we can use async loading with asyncio or take advantage of concurrent.futures.
Generalizing the cache function
As we noticed above, the fetch_transactions_with_cache() function is not reusable. If we want to cache different objects, resorting to copy and paste is the only option we have.
To address the issue, we convert the function into a generic class, where subclasses need to define two methods.
- How to fetch data from the upstream.
- For a specific bucket, what should be the cache key.
Here’s our generic fetcher.
class GenericFetcher(abc.ABC, Generic[T]):
@abc.abstractmethod
def get_cache_key(self, bucket: WeeklyBucket) -> str:
raise NotImplementedError()
@abc.abstractmethod
def get_values_from_upstream(self, bucket: WeeklyBucket) -> list[T]:
raise NotImplementedError()
def fetch(self, start_date: datetime, end_date: datetime) -> list[T]:
buckets = get_buckets(start_date, end_date)
model_type = self.get_model_type()
records: list[T] = []
for bucket in buckets:
cache_key = self.get_cache_key(bucket)
# Check if there's anything in cache
...
# Fetch the value from the upstream
value = self.get_values_from_upstream(bucket)
...
# Save the value to the cache
...
# Update the records
...
return [
record for record in records if start_date <= record.timestamp < end_date
]
Here’s our transaction fetcher as a subclass of the generic class.
class TransactionFetcher(GenericFetcher[Transaction]):
def __init__(self, wallet_address: str):
self.wallet_address = wallet_address
def get_cache_key(self, bucket: WeeklyBucket) -> str:
return f"transactions:{self.wallet_address}:{bucket.cache_key()}"
def get_values_from_upstream(self, bucket: WeeklyBucket) -> list[Transaction]:
return fetch_transactions(self.wallet_address, bucket.start, bucket.end)
Here’s how you would use it in real life.
fetcher = TransactionFetcher("1HesYJSP1QqcyPEjnQ9vzBL1wujruNGe7R")
transactions = fetcher.fetch(start_date, end_date)
Populating cache in the background
The caching is worth nothing if the cache is cold. With cold cache, the burden of populating it (and waiting for the response from the upstream) lays on the shoulders of the first user opening the page.
For a smooth user experience, we wanted to populate the cache for the most common metrics in the background. Overall, the task was relatively straightforward: we had to call TransactionFetcher.fetch() for hot keys. To schedule cache warmup jobs, we used flask-apscheduler and ran a separate process firing these jobs at specific times.
Here is a sample snippet from the cache warmup module.
@scheduler.task(
id="warmup_transaction_cache",
trigger="interval",
seconds=1000,
jitter=100,
)
def warmup_transaction_cache():
end_date = datetime.now(timezone.utc)
start_date = end_date - timedelta(days=30)
for wallet_address in WALLET_ADDRESSES:
TransactionFetcher(wallet_address).fetch(start_date, end_date)
Summary
I planned this post as a brief outline, but somehow it got out of hand and turned into a lengthy post with several technical details, digressions, and even a sample project.
Even in that size, the outline only sketches or misses some interesting optimizations we implemented in the dashboards. For example, the topic of proper background population and avoiding cache stampede is left out of the scope.
With that said, I hope that the provided techniques and code snippets can help you implement your own caching solutions with Python or learn something new about the Python ecosystem in general.